
As our context windows expand and our LLMs grow more sophisticated, we’re witnessing an interesting evolution in how we approach knowledge-intensive AI applications. Cache-Augmented Generation (CAG) has emerged not as a replacement for Retrieval-Augmented Generation (RAG), but as a thought-provoking alternative that challenges our assumptions about knowledge retrieval and context management.
The Evolution of Context
The journey of large language models has been, in many ways, a story about context. From early models struggling with a few thousand tokens to today’s architectures handling hundreds of thousands, we’ve seen a fundamental shift in how these systems process and understand information. This evolution naturally leads us to question our existing approaches to knowledge management.
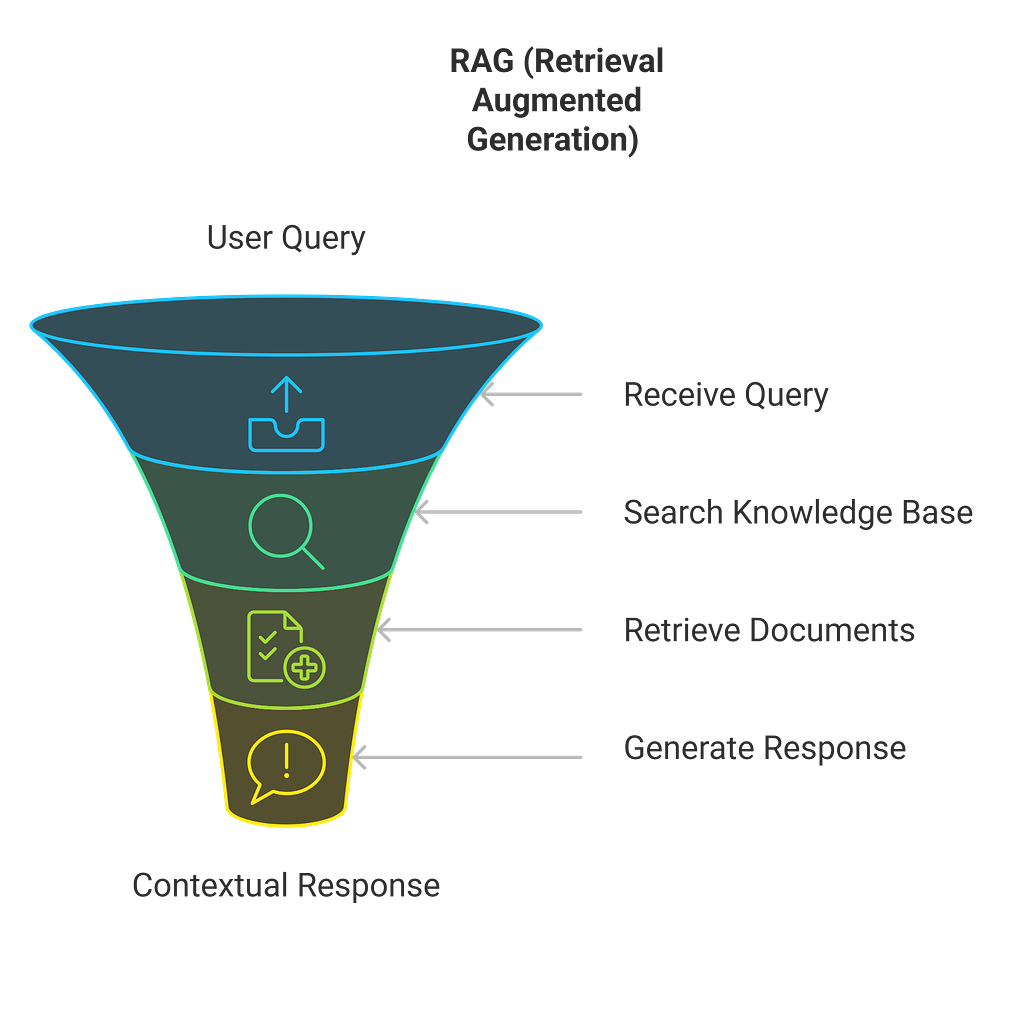
Traditional RAG systems were born from necessity. A clever solution to the limited context windows of earlier models. By retrieving relevant information on demand, we could theoretically access unlimited knowledge bases. But as with many evolutionary adaptations, what started as a solution has sometimes become a source of complexity.
Understanding Cache-Augmented Generation
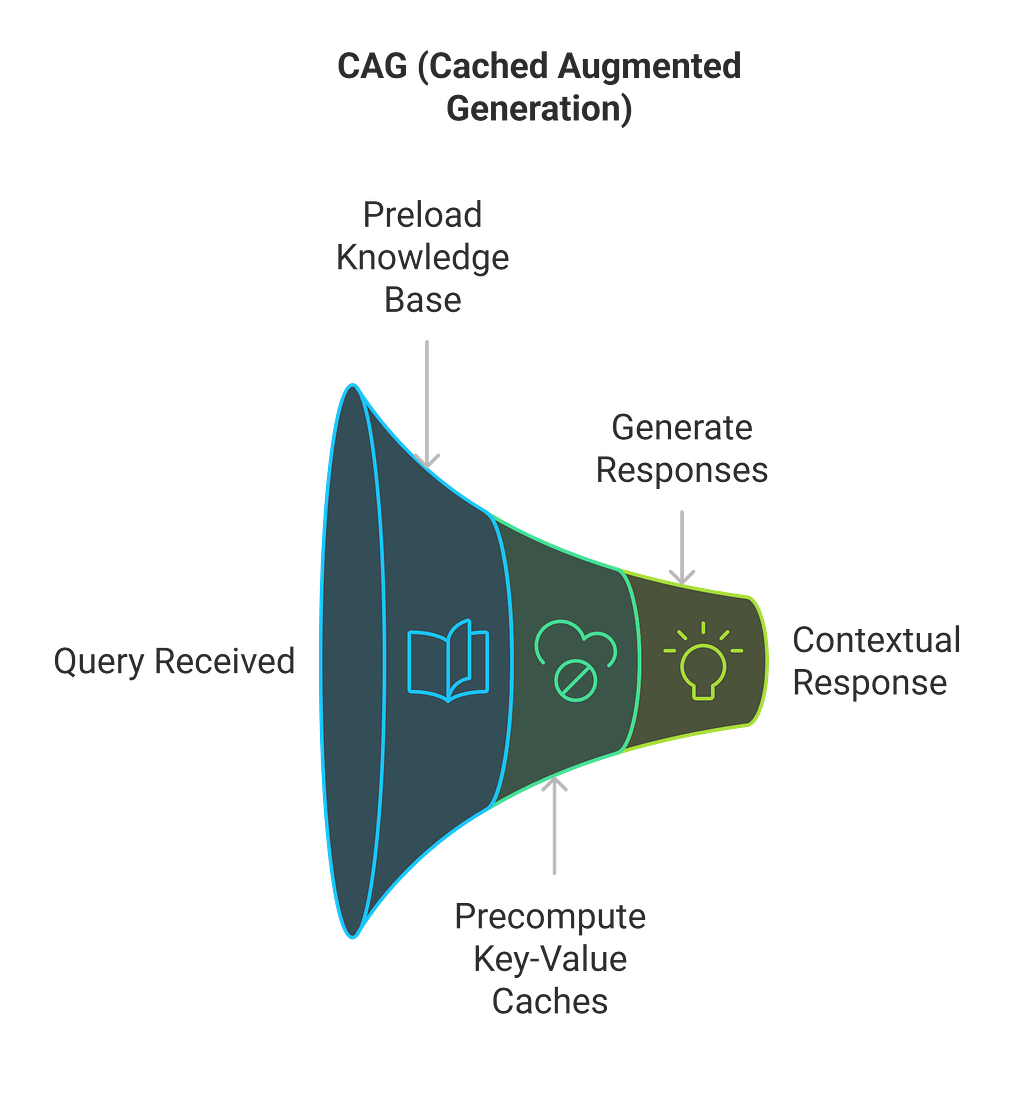
CAG takes a surprisingly straightforward approach: instead of building complex retrieval pipelines, what if we simply preloaded all relevant knowledge into the model’s extended context window, along with precomputed inference states?
This isn’t just about simplifying architecture. It’s about fundamentally rethinking how we manage knowledge in AI systems. Consider the parallels with human cognition: we don’t actively “retrieve” most information during conversation; we draw upon readily available knowledge in our working memory.
RAG’s Approach:
CAG’s Approach:
The Technical Reality
The implementation differences between RAG and CAG reveal interesting trade-offs:
- RAG optimizes for storage but pays in retrieval time
- CAG optimizes for speed but requires more upfront memory
Knowledge Freshness
- RAG can incorporate new information immediately
- CAG requires periodic cache updates
Scale Considerations
- RAG scales well with large knowledge bases
- CAG works best with focused, moderate-sized knowledge sets
When Each Approach Shines
The choice between RAG and CAG isn’t binary. It’s contextual. CAG particularly excels in scenarios where:
- Knowledge bases are relatively stable
- Response time is critical
- The total knowledge base fits within context limits
- System simplicity is prioritized
RAG remains valuable when:
- Knowledge bases are massive
- Information updates frequently
- Flexible retrieval patterns are needed
- Storage optimization is crucial
Looking Forward
As context windows continue to expand and model architectures evolve, we’re likely to see hybrid approaches emerge. Imagine systems that leverage CAG for frequently accessed knowledge while falling back to RAG for rare or updated information.
The real innovation of CAG isn’t just technical. It’s conceptual. It challenges us to rethink our assumptions about knowledge retrieval and context management in AI systems. As we continue to push the boundaries of what’s possible with language models, such paradigm shifts become increasingly valuable.
Implementation Considerations
For teams considering CAG, key questions to address include:
Knowledge Base Analysis
- How large is your knowledge base?
- How frequently does it update?
- What are your latency requirements?
System Requirements
- Available memory resources
- Processing power allocation
- Update frequency needs
Architecture Decisions
- Cache update strategies
- Fallback mechanisms
- Monitoring and optimization approaches
Cache-Augmented Generation represents an intriguing shift in how we think about context and knowledge access in AI systems. While it’s not a universal replacement for RAG, it offers a compelling alternative that might better suit certain use cases.
As we continue to explore these approaches, the key is understanding not just their technical implementations, but their broader implications for system design and knowledge management. The future likely lies not in choosing between RAG and CAG, but in understanding how to leverage each approach’s strengths for specific use cases.
This evolution in knowledge management strategies reflects a broader trend in AI development: sometimes the most significant advances come not from adding complexity, but from rethinking our fundamental approaches to problem-solving.
Note: This analysis is based on current research and understanding. As with all rapidly evolving technologies, approaches and best practices continue to evolve.